Console
Interview with
Tyson Kunovsky
CEO, CloudGraph
GraphQL API for your cloud resources..



What is CloudGraph? Why did you build it?
For organizations that are running workloads on AWS (and soon Azure and GCP), CloudGraph creates regular snapshots of your entire footprint. This allows cloud engineers to get instant insights on security compliance, billing, and asset inventories for all their environments, not just now, at any point in time since they hooked up their account (to CloudGraph).
Unlike provider consoles, CLI tools, and other tools that you have to spend time learning and pay a lot of money for, CloudGraph makes it really simple to ask questions about any environment such as: “Is the approved three-tier web stack for AWS that we planned the same as the three-tier web stack that we actually built?” “Do we have any public S3 buckets, unencrypted EBS volumes, internet-facing load balancers?”, or maybe “How much are we paying per day for each M5 EC2 instance in US East 1 on our two AWS accounts”?
With CloudGraph, you can do all three of these things in a single query from a single API, using read only access without installing any agents or software.
How would an engineer solve this today without CloudGraph?
If you want to figure out how to answer these types of questions today, the first thing is you’re going to need to be experienced with the cloud platform so you can understand everything that is running.
Then you're also going to have to run several CLI commands. You're going to have to know what they are, to search for the documentation, and spend a lot of time constructing these queries. They're very brittle. There's no type safety, there's no auto-completion. You're going to have to get back the results, process and aggregate the data yourself, and then figure out the answer.
In contrast, with CloudGraph you get built-in type safety, autocomplete and schema documentation. As you're writing, you can actually see what the possible values for selection are, no more over fetching or under fetching. It's all declared using GraphQL.
We see a future where 90% of the Fortune 500 are multi-cloud - Azure, GCP, and AWS. We want to allow people to query their entire cloud footprint from a single place with a single query and understand not only what you have running, how it's configured, but what that means from a DevSecOps perspective. We want to allow you to have that single source of standardized truth.
We're working on rolling out providers, beyond AWS, so you don't have to have the domain expertise to operate in all three different clouds. You can get up and running really quickly by just having an understanding of the common set of APIs that we're building.
What does a "day in the life" look like for you?
I live in an 800 square foot apartment in downtown Chicago, and I started CloudGraph and AutoCloud with my wife, Evelyn.
One of the few things that kept me sane going through COVID and lockdown is going to the gym in the morning! One of my good friends opened up a CrossFit gym and made me sign up and here I am two years later, still into it.
After the gym I’ll come home and typically have morning leadership check-ins to make sure that we're on the right direction for things, then we have a stand up for all of the different teams. We have three internally and then a scrum of scrums a couple of days a week.
Otherwise, being CEO involves lots of meetings, sales calls, and investor relations. If I can find the time, I try to do some PR reviews, and sometimes even get lucky and write a little bit of code! I'm getting to the point in my career where I've been an engineer for a long time and I still find joy from coding. There's such little time in the day to do it, but I'm just happy that I can still be a tiny bit hands-on and contribute a little bit here and there.
What is the team structure around CloudGraph?
From a hierarchy perspective, we are a very flat organization. I was previously the head of technology at a large consulting company where we had many different levels of engineers: senior engineer, architect, senior architect, director, principal, etc.
At AutoCloud we've been lucky with our hiring process in the way that we've structured our teams. We can get away with a really flat organization for now. We have senior engineers and directors of engineering. These are our two hierarchies, where the director would report to the CTO.
From a team perspective, we have three internal teams that are working on AutoCloud and CloudGraph. The first is our open source team - they're the folks that have built CloudGraph from scratch.
We then have our SaaS platform team - internally we call that the enterprise team - that's building out the various page features of CloudGraph for AutoCloud. Next, we have what we call the ‘bridge team’. The function of the bridge team is to sit between the open source and the enterprise team and take whether it be community pull requests or new features or things that occur first in the open source platform, and help integrate those into the enterprise platform to make them more robust, and more of a managed service. That's the structure of how we have things today.
How are you thinking about the relationship between the commercial SaaS business and the open source project?
There have been a lot of companies in the last five years that have had a lot of success with bottom-up developer plays, where we can build tools that are genuinely useful, that don't have limits on features for open source.
When you get beyond a certain scale, it just makes sense to not have to do that yourself and have something that's a little bit more managed that has redundancy, backups, scheduling features. For example, we take care of data security for you.
When we conceptualize the open source and closed source worlds, our purpose and our mission are to serve developers. Open source is in our DNA and the most important thing we're doing, but obviously, as a company, we need to make money. We've enhanced what CloudGraph does in AutoCloud to be able to pay the bills and keep the lights on.
How did you first get into software development?
I got into coding back in high school. My parents helped start a company called the Gottman Institute, which for over 40 years now has researched couples relationships. They can actually predict with 94% accuracy, whether a couple will stay together or get divorced just by watching them fight for 15 minutes.
There's a lot of fascinating maths and there's something called Specific Affect Coding System or, "SPAFF", that analyzes the dominant effect on people's faces and can give you certainty of how stable this couple is. At the time, the company didn't really have an idea of how to digitize its business. There were a lot of forms, a lot of seminars, and a lot of workshops.
My first coding was in relation to that. They needed help with websites. I taught myself a bit of coding in high school and they had this interesting product called the Relationship Checkup Site, which is where I tried to become a bit more of a hardcore engineer.
This was 2006 when Ruby on Rails had just become fully released. I think we were in Rails 1 or 2, and I built out a product that would essentially take inputs from 200 separate questionnaire questions that each member of the couple would fill out and then give them a score to help determine the overall satisfaction in the relationship, and figure out how to make the relationship better overall.
I taught myself and had a lot of mentors that helped me improve my skills. That was my first foray into software engineering.
I started coding in HTML, then basic JavaScript, a little bit of jQuery and CSS. Through the years I've used all manner of frameworks and languages. I've used Python and Django quite extensively. I've used Rails, Java, JavaScript, TypeScript and today from a tech stack perspective, we are mostly a TypeScript shop.
There's a lot of benefit in having a true full-stack platform where if developers know JavaScript, you can get good at React on the frontend, which we use, but also move around to work on the backend as well.
With a senior team, we've all coded a lot of things. We don't want people to get bored. TypeScript allows us to really move people around.
We also use Prisma, the graph ORM, which I absolutely love and would highly recommend to anybody, and we leverage Terraform. We run an EKS on AWS and a few other tools and technologies, but at a high level, mostly TypeScript.
What is the most interesting development challenge you've faced working on CloudGraph
We're building a real-time streaming system for one of the world's largest AWS users. They have a fascinating problem, which is that they cannot make requests against their AWS data because their footprint is so large, that their requests just time out. They have tens of thousands of EC2 instances running on AWS which means we’re always hitting the AWS rate limits.
Instead, we allow our customers to query our database instead of AWS. This is Dgraph behind the scenes, which we can scale to meet their requirements. We keep that up to date by streaming CloudTrail updates from AWS.
We view this as a shift away from the single source of truth from the cloud providers themselves to a more scalable distributed platform like CloudGraph that people can extend and have a lot more flexibility, using and operating on.
How do you handle querying the historical state?
The cloud is living and breathing. Maybe you're using something like Auto Scaling, where you have different nodes or pods or instances being spun up and down. What we're trying to do with CloudGraph is allow people to look at their cloud at any point in time. To that end, we create different versions and in each of our versions we have the entire representation of that footprint. We're working on an ability for the open source community to query between versions and be able to check a value here and see what that value was previously.
We want to allow you to understand not only what your state is and how it's changed, but the "so what" ramifications of that from all the different DevSecOps perspectives that I mentioned earlier.
What’s the most interesting tool or tech you’re currently playing around with?
There’s a couple of interesting tools that we're playing around with now.
Prisma isn’t new but using it as a GraphQL ORM has become much more robust in the last few months. It's a wonderful way to be able to interact with a relational database. I believe they have MongoDB support as well now.
On the front end, you can use something like Apollo and on the back end, you can leverage Prisma to be able to interact with your database in a really type-safe declarative fashion. You might be able to tell that we like GraphQL!
We also love Dgraph, Dgraph is an internet-scale graph database that allows you to write GraphQL queries and mutations to be able to interact with your data.
There are other databases out there that are dipping their toes into GraphQL, such as Neo4J, but we really like Dgraph because of how high performance it is. There's a learning curve you have to go through to be able to leverage it but when we think of trends in open source and developer communities in general, around the democratization of technology, we'd like to make this as easy as possible through GraphQL, hence the decision to use Dgraph and to allow anybody to be able to query their data in that fashion.
Why did you pick GraphQL as opposed to SQL?
Firstly, it can be really annoying to have to join across many tables to get a result. Think of a complex query where you start with a VPC and then you want to understand the EC2 Instances that are associated with that VPC, then go to the ELBs and security groups and so on. To do that in SQL is going to require a lot of joins to get to the data that you need. With something like GraphQL and GraphQL Playground, which ships with our tool, that's all built-in. You don't need to understand how the joins work.
You don't need to understand how any of this comes together, and you can write these very robust, quick queries to get back only the data you want no more over fetching or under fetching - all of the data you want and nothing more is there.
There are also severe performance concerns when it comes to using SQL at an enterprise scale. If you have many accounts and you have a very large dataset, you're doing a lot of different joins to get the data. There's going to be a lot of latency.
We believe that GraphQL is the future and we believe that moving forward as we start to have better data access and accessibility overall to data, GraphQL is going to be the top technology of choice to help facilitate that.
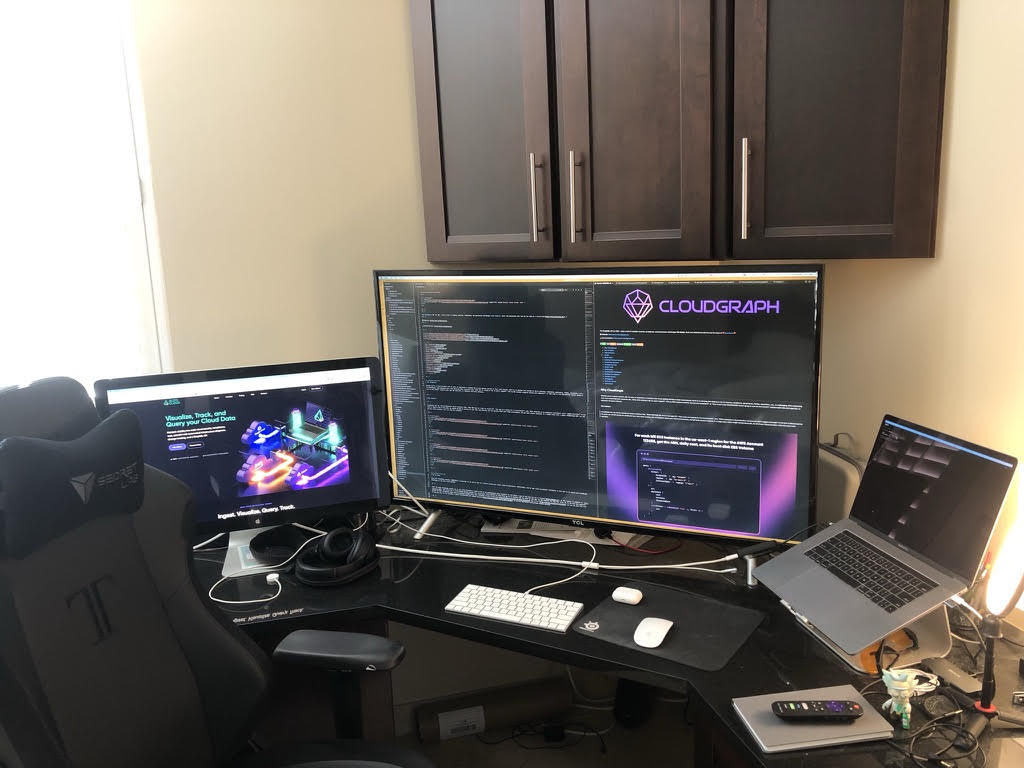
Describe your computer hardware setup
From a hardware perspective, I'm currently running a 15 inch, 2017 MacBook Pro with 15GB of RAM and a 500 GB flash drive. I use three monitors. I have my laptop, and a Thunderbolt display, then I have a 43 inch TV. I use this as a monitor and it is fantastic from a coding perspective.
I have this massive screen real estate with the ability to see so much. When you're working across a complex project, with many different repos and code windows having that context is useful. I use the standard Apple keyboard.
Describe your computer software setup
OS: macOS.
Browser: Chrome.
Email: Spark.
Chat: Slack.
IDE: VS Code.
Source control: Git.
Describe your desk setup
Nothing fancy. The fanciest thing that I have is a Secretlab TITAN chair.
When coding
Daytime or nighttime? Nighttime.
Tea or coffee? Tea.
Silence or music? Silence.
What non-tech activities do you like to do?
I love skiing. If I had my way, I would try to ski 300 days a year!
I also am really into motorcycling. It’s a wonderful activity that my father and I do every few years. If we have the time, we try and go on a trip somewhere around the world, and try and do a two week motorcycle excursion together where we're unplugged. It's just us, and we can really bond and have a nice time.
During the course of the pandemic, I've also really gotten into working out with CrossFit. Those are kind of my big three.
Find out more
CloudGraph gives your cloud resources a GraphQL API. It was featured as an "Interesting Tool" in the Console newsletter on 11 Nov 2021. This interview was conducted on 27 Oct 2021.
Subscribe to the weekly Console newsletter
An email digest of the best tools and beta releases for developers. Every Thursday. See the latest email