Console
Interview with
Beyang Liu
CTO, Sourcegraph
Code search engine.




What is Sourcegraph? Why did you build it?
Sourcegraph is a code search engine. The idea is that you type in a query - a string literal, an error, or a function name - and Sourcegraph helps you get there.
The primary use case is searching over large codebases, or large effective codebases. I don't know if there's such a thing as a small code base anymore, just because everyone has a dependency on a lot of open-source projects. Your effective code base is in the form of what you're pulling in, the transitive closure of your dependency graph. The idea with Sourcegraph is that you can quickly locate any portion of code in that giant, superset of code that's relevant to you. Or, potentially things outside of it that you're trying to discover and quickly dive into the code to build a working understanding of it.
Sourcegraph is search first and foremost, but there's also a code browser attached to it. That's important because the task of understanding code does not stop at getting to a particular first location in code. Jump to a definition, find references, these kinds of basic navigational primitives are really essential. We all appreciate those as developers. I think that's one of the things you do first when you set up a new development environment. We want to make it so that you don't have to set up a development environment to get that type of functionality. You can seamlessly jump to any point in the world of code and navigate the code as if you're navigating the web, with hyperlinks that you can just click on to build a deep working understanding of code.
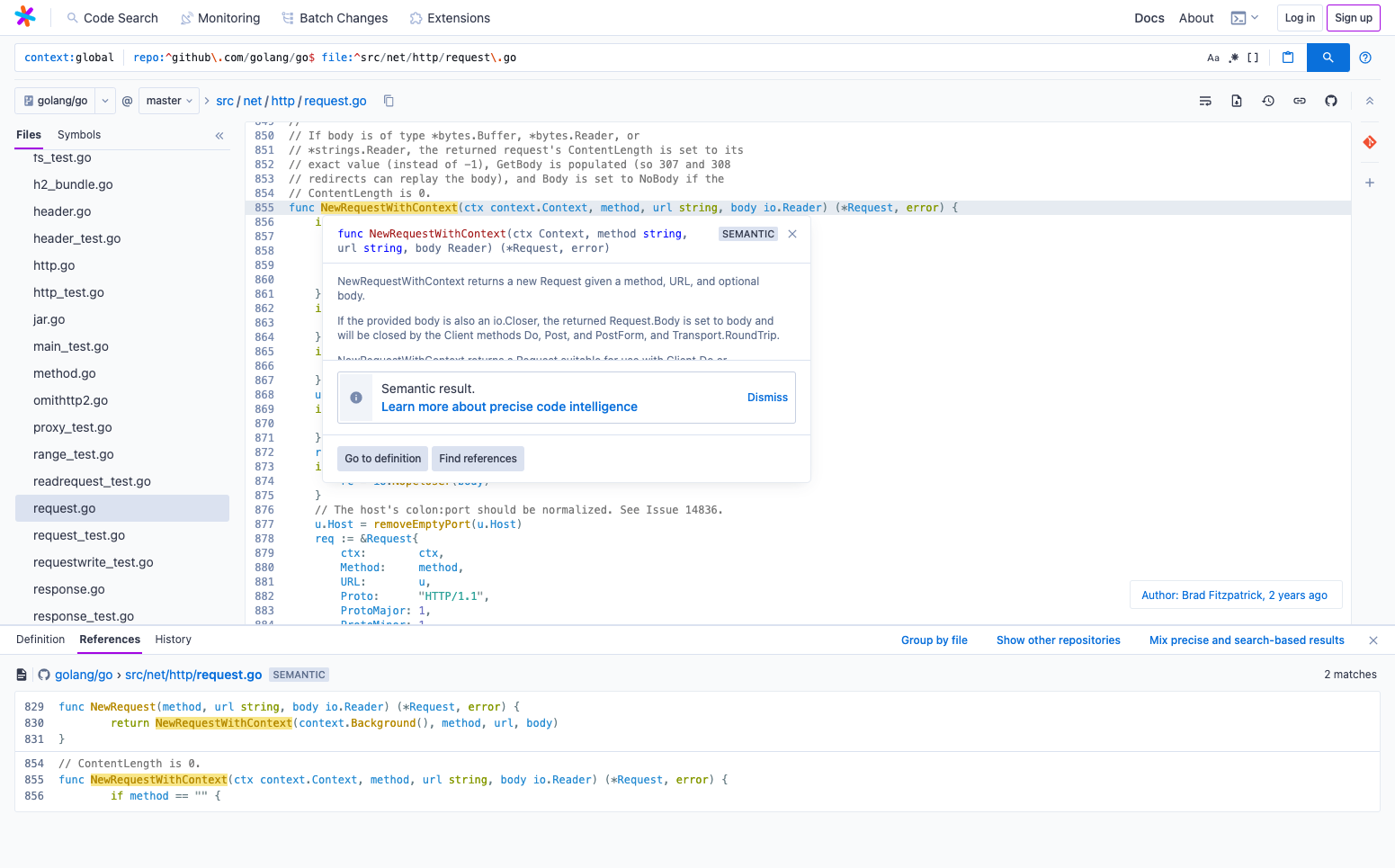
How were developers solving this before Sourcegraph?
With a lot of duct tape or using a lot of command line tools like Grep and modern variants like ripgrep. Maybe the search in your editor. The issue with those is that it's searching all over your local machine. You have to clone the code, and that's enough friction that most people don't want to do that. Even after you've cloned it, in order to get the navigational primitives you have to set up code intelligence and the development environment. It's got a little bit easier with cloud IDEs now, but oftentimes you still don't have code intelligence. If you want to cross a dependency boundary or search over a larger set of code, those don't really help with that.
Some people use GitHub but I don't think they've really prioritized search, at least in the sort of depth that I think it deserves. There's some organizations that have built internal code search engines and there’s some open source projects too.
Facebook has an internal code search engine. Mozilla has one for all the Firefox and related code bases. There's one for the Debian and Linux community that a friend of mine, Michael Stapelberg built. These are all precursors that demonstrate the need, especially as organizations and projects expand in scale, both in terms of human head count and the amount of code that they deal with. Google has one that people swear by. In fact, one of our biggest sources of new users and customers is people leaving Google.
We think it's time to take all the lessons learned from those, roll it into something that just works well universally for every language, for every code host, for every sort of development org. We’re building it into this comprehensive, Google-like search engine, not just a search engine that's targeted at one particular corpus of code, but the worldwide, global human knowledge graph that is built into code.
We want to make it so that you have a single search box that lets you jump anywhere in the world of code, that understands what code is relevant to you and allows you just to walk that knowledge web the same way you do using the combination of Google and hyperlinks on the internet.
I think that is the next stage. The next big thing in software development is getting it to the point where search is kind of a basic starting point for a lot of developers when they go and understand code. Right now, I think we're still in the Yahoo era of code, where a lot spreads through word of mouth or, maybe there's blogs you follow, or you're searching for stuff using Google search, or just finding it on GitHub. There's not really a direct discovery mechanism that shows you relevant matches for a specific thing that you want to take a look at in the moment.
Coming from GitHub search, what would someone notice is different with Sourcegraph?
They'll find that Sourcegraph search is much more intuitive. GitHub search is weird. For many years, I think what they did was they dumped code into a giant Lucene backend or ElasticSearch backend, but these are optimized for prose. Code is a very different animal. With GitHub, a lot of times you'll type in a query and it'll treat it as a ‘bag of words’ query, where each token is kind of treated like a separate thing. They'll surface results that are not necessary. They don't include all those tokens together in the way that you intended. Code search tends to be more like: “I want this specific error message”, or “here's a regular expression that I want to match against”.
Those things just aren't possible in GitHub. We have built code search on top of several different code search engines. We use a project out of Google called Zoekt, which is based on a version of Google's internal code search. That's one of our search backends. We have multiple search back ends that are optimized for different types of queries that developers often do. We've tried to combine them into a user-friendly, but also powerful and expressive front end query syntax that gives you the whole spectrum of things you might want to search for. From just typing in that error message that you want to jump to immediately to really powerful and fine grain filters and/or nestable expressions, things like that.
What does a "day in the life" look like for you?
It's very bimodal. I have meeting days and non-meeting days.
Meeting days are when I’ll stack a bunch of meetings with various people inside the company to talk about the state of projects and planning. I’ll also do external meetings with users, customers, and getting the word out.
On non-meeting days, I like to devote that to playing around with code, trying out specific new features of Sourcegraph to build a stronger intuition around how I want to incorporate that into my workflow. I end up doing a lot of email on those days too, catching up on various other things.
How much time do you get to code?
Right now it's averaging maybe one day a week, which is not great. I want to get back to doing more. I was just chatting with Mitchell Hashimoto at HashiCorp where he did this arc where he stopped coding for a period of two years, then he has gradually worked his way back to coding four or five days a week now. I was thinking okay, maybe he can share some insights there!
What is the Sourcegraph team structure?
The company as a whole is around 160 people now. Product and engineering is around 60. We have around 10 people on the product team and 50 on the engineering team. We're split into different functional groups around a specific area in code. We have a front end platform team and a core application team, and product oriented teams that are feature verticals like code insights, batch changes or search code intelligence.
We're a group of people who are really passionate about developer tools and dev productivity. I think it's one of the most fun things you can work on as an engineer. You get to wear both the development and product hat too, because you are the target user. Interests are very well aligned between the company's interests of building a big business and growing usage, and your own interest of just scratching your own itch.
Are you an entirely remote company?
We went all remote in January of last year, which turned out to be pretty good timing. We'd always been remote friendly. A number of our first few team members were based outside of where I'm located. Our CEO, Quinn Slack is located in San Francisco. We had a teammate in Arizona, a teammate in South Africa and a teammate in Germany. We very quickly adopted practices that prioritized geographically distributed communication.
We kept the office for a while, but at some point we just realized, coming into the office day-to-day, didn’t deliver a ton of value in face-to-face communication. We were getting that from getting people together in one location to attend a conference, or to do an offsite. The day-to-day in the office was, at least among our team, just a lot of sitting at a desk and typing stuff into the keyboard, building stuff.
The conversations that did need to happen were happening well enough with us working remotely, so we thought why are we doing this in the office? It was nonsensical, especially for the people in the Bay Area who had longer commutes. All this time could be better spent either building stuff, or with your family or doing something else rather than sitting in a car or a train heading into the office. We're all remote, and hiring from everywhere.
How did you first get into software development?
I had a really good sixth grade teacher, Mr. Thompson. He tried to get me into Visual Basic. I think I made a simple program, but it didn't really stick. The interface colors were super gray and I don't really think I really knew enough at that time to be like, oh, here's where I could take this. So, I kind of dropped that for a bit.
I always loved maths and science, so that kept me adjacent to computers. In high school, I ended up getting back into it, because I had one of those TI-83 graphing calculators that it seems every high school maths student got at some point. That had a dialect of BASIC that you could program. I was fortunate enough to get a version that came with this giant reference manual that had documentation about the syntax and what you could do with it.
I started out just coding in formula solvers, but worked my way up to various things, like trying to display cool animations on the screen. That was really fun. Computers seemed like a good union of my kind of intellectual interests so I ended up studying it.
I took a CS class in high school that was Java, and then C++. Next I did a bunch of MATLAB in college, because I did some machine learning research, along with some Python and Java. Then I found Go and I'm mostly Go and TypeScript based these days. Those are my go to languages. There's other ones that I think are cool, like Rust that I've been meaning to get into. Zig seems cool. I don't know if people have heard about that, but a couple of folks on our team are into that, and the creator, Andrew Kelley, seems really cool.
What's the Sourcegraph tech stack?
Mostly Go on the backend and TypeScript on the front end.
We have a bunch of different languages, because we want to provide really precise, compiler-accurate code navigation for all languages. I think the best way to do that is to hook into the compiler API or some static analysis library. Those are often written in the language that they analyze.
What's the most interesting challenge that you've faced building Sourcegraph?
There's a ton of interesting challenges. One of the appealing things about what we do is that there's deep technical problems. Scaling code search is a challenge. I don't think anyone's making that work at a global scale for all the different types of queries that people want to perform. It is super interesting, playing around with different indexes. Working with trigram indexes and storing stuff in memory has been an interesting challenge.
Precise code intelligence has been really interesting too, because you have to build this out for a bunch of different languages. There are certain things that are kind of common. We've gone through multiple iterations of language-agnostic protocols. Currently we're using LSIF, which is this serialization format that's a sister to LSP. Originally created by Microsoft, it's now very popular in the open-source world.
Before that, we went through a couple of iterations of protocols. Our precise code intelligence efforts actually predate LSP. We had this thing called Source Load back in the day, so it feels like we've been working on this problem for forever. It turned out to be a much bigger rabbit hole than we really anticipated, both the language level support, and also integrating with all the different build configurations. It's not enough to hook into the compiler API, especially when you get into private code. There's just so many idiosyncratic ways of building software that you encounter.
We want to be able to support all of that because it’s necessary in order to get this compiler accurate precision in the code navigation for “jump to definition” and “find references” that you just cannot find anywhere else outside of Sourcegraph.
Another big challenge is that we index public code and private code. The private code tends to be self hosted on premises, so just making Sourcegraph deployable into customer environments has gotten a lot easier with Docker and Kubernetes.
We want to index code in a way that works across repository dependency boundaries without any sort of manual setup, so we're growing our search index this year. The cloud version of Sourcegraph launches in public beta on 19th Aug where we’ll have 1 million open source repos indexed - any public, open source repos with 1 or more stars - and then 5 million by the end of the year.
Ultimately, we want to be able to cover all of the open source universe. We want to build a global graph of code, essentially the hyperlink network for the world of code, so that you never ever have to fuss with a Git clone or setting up your development environment to be able to just seamlessly navigate code through dependencies. I think we're getting there. By the end of the year, we'll have something that's truly magical in terms of the type of code browsing and exploration that it can enable.
What’s the most interesting tool or tech you’re currently playing around with?
We use a couple of cool tools on the dev ops side. Sentry for monitoring and Honeycomb for observability. Lightstep is really good for distributed tracing. And of course Grafana and Prometheus.
I've heard a lot of good things about fzf, the Fuzzy File Finder. I've been meaning to try that out. Ripgrep is great for command line search. It's a great grep replacement. Faster in my experience, with better defaults, so you don't have to Google for the proper command line flags every time you want to use it.
I also have this side project that I'm working on, which is just coming up with
a better way to customize the YAML configuration of our Sourcegraph Kubernetes
deployment. There's so many different ways of customizing that in the Kubernetes
ecosystem right now. Kustomize and
Helm have configuration languages, like
Q
and Dhall. I think they're all very interesting and
they serve their purpose. It just doesn't serve our exact purpose at the moment.
I'm trying to write a simple program that will take a base, like Kubernetes’
manifest template and apply a series of transformations that a customer might
want to do, while preserving the vanilla Kubernetes aspect of it so you can
still use kubectl apply. That's a side thing that I hack on.
The team at Sourcegraph are doing lots of interesting projects at the moment. We have an engineer on the team named Rok Novosel who started building a search notebook feature, which is kind of like taking Sourcegraph's search and combining it with some principles of an IPython notebook or Jupyter notebook. That's a use case we encounter a lot, where someone's like: “The way I use Sourcegraph, it's really kind of like an investigation. I want to write down notes in markdown while I do successive queries to narrow down on the answer of some question I'm going to ask.” Or: “I'm trying to write up a doc for people new to this part of the codebase.” Onboarding, and giving them an intro to all the key components. He hacked that together as a side project, and now we're trying to roll it into the actual app.
Describe your computer hardware setup

My main machine is a Dell XPS 15 circa 2018 or 2019. I got the most powerful version I could get - 12 cores and 30GB of memory. It's a laptop, but I essentially use it as a desktop right now. I have a chiclet keyboard that seems close to the standard Apple keys, but compatible with Linux. I also use a wireless mouse that has side buttons on each side that do different things. One side is for scrolling up and down. And the other one is for back and forth button on the browser.
Display-wise, I have a pretty big monitor. It's the 32” Samsung Space Monitor. I used to have two monitors, but over the years I found the second monitor just to be more of a distraction. I also have a Rode Procaster and I set up my old DSL as a camera during the pandemic. There's an open source library that allows you to set up any old DSLR as a webcam.
Describe your computer software setup
OS: Ubuntu 18.04 + i3.
Browser: Brave.
Email: Gmail.
Chat: Slack.
IDE: Emacs running in a Tmux panel.
Source control: Git. We're on GitHub as our code host.
Describe your desk setup
I have a standard black Ikea desk, and I don’t know what the chair is, but it’s well padded, and it doesn't have wheels. I hate chairs with wheels.
When coding
Daytime or nighttime? Daytime.
Tea or coffee? Decaf coffee, and then tea in the afternoon.
Silence or music? Silence.
What non-tech activities do you like to do?
A lot of my activities revolve around learning new things. Reading stuff on the internet that's interesting - technical blog posts, philosophy, economics, microeconomics … things like that.
I'll occasionally play music, I’ve got a digital piano that's fun to bang on now and then. On the weekends, I like driving around and hiking. There's a lot of good nature and scenery in the Bay Area. I try to work out regularly as well. As I've gotten older, I've found exercise has an outsize impact, positive impact on mental state and ability to focus.
Find out more
Sourcegraph is a code search engine. It was featured as an "Interesting Tool" in the Console newsletter on 19 Aug 2021. This interview was conducted on 17 Aug 2021.
Subscribe to the weekly Console newsletter
An email digest of the best tools and beta releases for developers. Every Thursday. See the latest email